
Hystrix ve Resilience Patterns
Bu yazımızda Netflix firmasının uygulamalara dayanıklılık sağlamak amacıyla(resilience patterns) geliştirdiği Hystrix’ten bahsederek temel resilience patternlardan olan circuit breaker ve bulkhead patternları örnek üzerinde incelemeye çalışacağız.

1. Hystrix Nedir?
Hystrix; Netflix’in open source olarak yazılım dünyasına sunduğu ve dağıtık sistemlerde bağımlılıkların hata durumlarına karşı önlemler almak ve yönetmek amacıyla ortaya çıkmış bir kütüphanedir.
Ortaya çıkma sebeplerini Netflix kendi Github hesabında şu şekilde bahsediyor;
-
Bağımlılıklardan kaynaklı gecikmelerden ve hatalardan korunmak.
-
Kompleks dağıtık bir mimaride hataların katlanarak büyümesini engellemek.
-
Hata ortaya çıktığında erkenden fark edilmesini(fail fast) ve düzeltilmesini sağlamak.
-
Geri dönüş(fallback) metotları belirleyerek hata durumlarında veya sınırların aşılması durumlarında yönlendirme yapmak.
-
Gerçek zamanlı görüntüleme ve alarm mekanizmaları kurmak.
Hystrix’in çözmeye çalıştığı problem, dağıtık mimaride yüzlerce servisin olduğu sistemlerde daha çok önem kazanmaktadır. Bir veya birkaç mikroservisin geç yanıt dönmesinden, hata ile karşılaşmasından kaynaklanan hasarı kullanıcı deneyimine yansıtmamaktır. (Netflix örneğinde anlık altyazının alınamadığı durumda kullanıcının film veya dizileri izleyebilmeye devam etmesi gibi.)
1.2 Resilience Patterns
Uygulamaların daha dayanıklı olmasını sağlamak için aşağıda popüler olan resilience patternlar listelenmiştir. Bu yazımızda aşağıdaki iki tanesini inceleyeceğiz.
-
Circuit Breaker Pattern
-
Bulkhead Pattern
-
Retry
-
Fallback
-
Timeout
-
Stateless Services
1.2.1 Circuit Breaker
Circuit breaker, servislere erişimde belirlenen hata oranlarının aşılması durumunda aktifleşerek hata alan servisin kısa süreli(sleep window) izolasyonunu sağlayan(circuit open) bir yaklaşımdır. Bir süre sonra servisin durumunun düzelip düzelmediğini anlamak için birkaç request yönlendilir ve yanıtın başarılı alınıp alınmadığı kontrol edilir(half open). Eğer yanıtlar başarılı ise devre kapanır(circuit closed) ve servis normal akışında devam eder.
1.2.2 Bulkhead
Bulkhead pattern, bir serviste yaşanan gecikmelerin veya timeoutların uygulama sunucusundaki tüm threadleri hızlı bir şekilde tüketmesini engellemek için kullanılır. Farklı bir deyişle bir servisin veya servis grubunun eşzamanlı maksimum n kadar requeste cevap verebilmesini, threadi tüketebilmesini, garanti altına almaktadır. Bulkhead sayesinde ilgili uygulamanın belli bir servis grubu yanıt veremez olduğunda diğer servislrein hala çalışıyor olması sağlanır.
1.3 Hystrix Nasıl Çalışıyor?
Hystrix, tüketilen tüm servis çağırımlarını **command pattern **yardımı ile sararak farklı bir threadde yönetmeyi tercih etmektedir. Bu sayede kendi tuttuğu çağırım metriklerine göre gelen isteklerin sürelerinin, adetlerinin, hata oranlarının belirlediğimiz aralıklarda kalmasını sağlamaya çalışır. Adım adım neler yapıldığını inceleyelim;
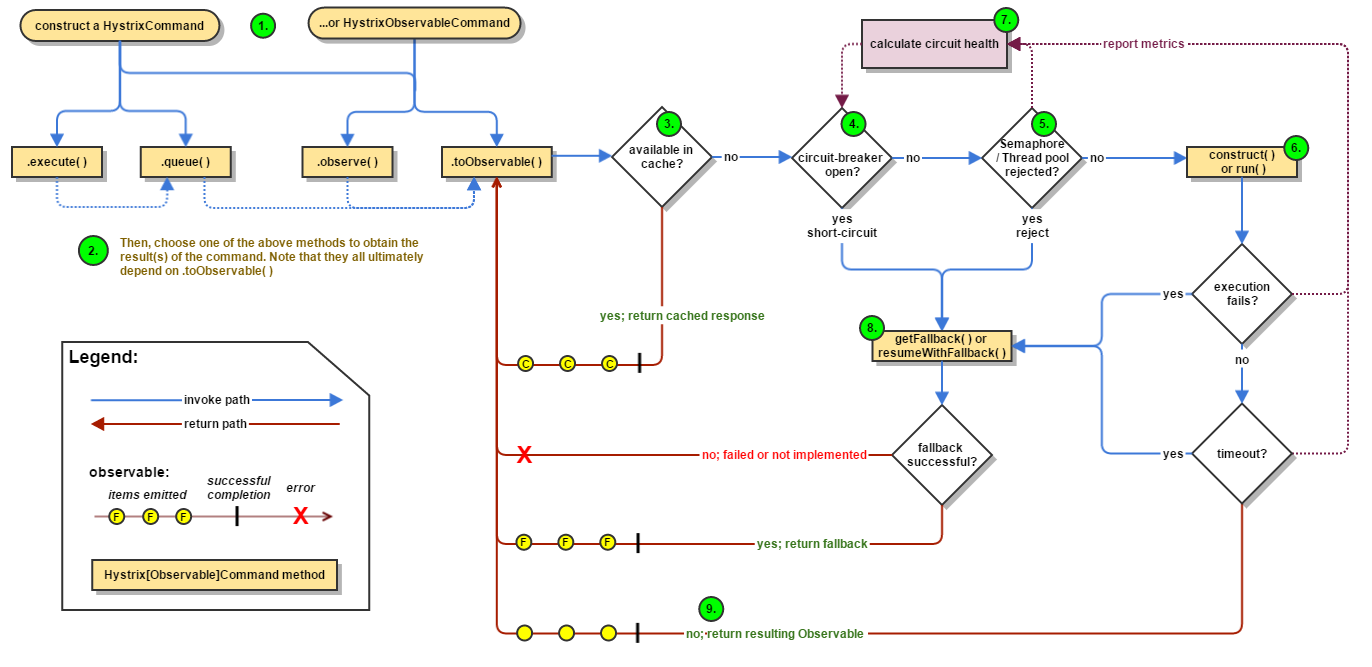
-
HystrixCommand veya HystrixObservableCommand oluşturulur.
-
Command tetiklenir ve çalıştırılır.(execute, queue, observe, toObservable)
-
Bu command için request caching açık ise response cachede var mı kontrol eder ve varsa anında döner.
-
Caching kapalı ise command execute edildiğinde circuit breaker açık mı diye kontrol eder. Eğer açık ise (buna tripped de denir) komut çalıştırılmaz ve fallback metoduna yönlendirilir. Eğer circuit breaker kapalı ise thread veya queue kapasite kontrolü yapılır.
-
Threadpool veya queue tam kapasitedeyse command çalıştırılmaz ve direk fallback metoduna yönlendirir. Aksi durumda command çalıştırılır.
-
Command çalıştırıldığında (ayrı thread kullanıldığında) eğer çalıştırma belirlenen timeout süresinde bitmez ise TimeoutException fırlatılır ve fallback metoduna yönlendirilir.
-
Herhangi bir hata alınmaz ise loglama ve metrik toplama işlemlerinden sonra response dönülür.
-
Dönülen responselara ait metrikler(success, failure, rejection ve timeout gibi) sonraki commandların çalıştırılması esnasında istatistik olarak kullanılacak ve commandın akıbetini belirleyecektir.
1.4 Hystrix Configs
Aşağıda thread pool ile ilgili temel konfigürasyonları inceleyelim.
1.4.1 Threadpool Config
coreSize: Hazırda bulundurulan thread sayısıdır.
maximumSize: coreSize geçildiğinde çıkılabilecek maksimum thread sayısıdır.
allowMaximumSizeToDivergeFromCoreSize: maximumSize değişkeninin etkin olmasını sağlar. Tipi Booleandır.
keepAliveTimeMinutes: coreSize aşıldığında açılan threadlerin kullanılmadığı taktirde ne kadar dakikada kapatılacağı bilgisidir.
1.4.2 Circuit Breaker Config
requestVolumeThreshold: Hystrix’in hata oranlarını hesaplamak için son kaç adet isteği dikkate alacağı bilgisi
sleepWindowInMilliseconds: Circuit breakerın open statüsünden half open statüsüne geçmek için bekleyeceği süre
errorThresholdPercentage: open statüsüne geçmek için hata oranı eşiği
1.4.3 Execution Stratejileri
Hystrix gelen isteklerin varsayılan çalıştırma stratejisi olarak THREAD yöntemini kullanmaktadır. Bu stratejileri inceleyelim.
1.4.3.1 Thread
Thread isolation; isteklerin ana threadler yerine fixed bir threadpoola taşınarak yönetildiği yöntemdir. Bu yönemde kullanılan sunucu thread adedi artacaktır. Yüksek yük altında bu ek bir maliyet yaratabilmektedir. Ancak isteğin tam izole bir threadde yönetilmesi bu yöntemle mümkün olabilmektedir. Özellikle timeout senaryolarını yönetebilmek açısından bu bir avantaja dönüşebilmektedir.
timeoutInMilliseconds: Ayrı olarak açılan thread’in time out süresi (sn).
1.4.3.2 Semaphore
Semaphore isolation, isteklerin ayrı bir threadde yönetilmediği yöntemdir(örneğin tomcatin açtığı web thread pool threadinden devam eder). Hystrix komutunu bu threadde çalıştırır. Belirlenen max eşzamanlı çağırım sayısına kadar izin verir. Ayrı bir thread olmadığından timeout alırsa thread isolationdaki gibi yoluna devam edemez.
maxConcurrentRequests: Eşzamanlı karşılanacak maksimum request sayısı.
Diğer tüm configler için Hystrix’in ilgili github wiki sayfasından bakılabilir.
1.4.3 Configleri Nasıl Ayarlamalı?
Hystrix’i projemizde kullanma kararı aldığımızda konfigürasyonun nasıl yapılması gerektiği ile alakalı kafamızda çokça soru işaretleri oluşacaktır. İhtiyaç duyulandan az kaynak verdiğimizde uygulamalarımızın çoğu isteğinin reddedilme ihtimali bulunmaktadır. Ya da gerekenden fazla kaynak verirsek patternlerden verim alamama gibi bir ihtimalimiz olabilir. Hystrix dökümantasyonunda bu konuda bir kesinlik olmadığını söylerken live sistemlerde zaman içinde doğru değerlerin bulunacağından bahsediliyor.
Hystrix’i hayatımıza dahil ettikten sonra uygulamalarımızı canlı ortamda izlerken hata oranlarının arttığını gördüğümüzde Hystrix’in reject ettiği isteklerin artışı bizi ister istemez config değerlerini arttırmaya zorlayabilir. Değerleri doğru bir şekilde verdiğimize inanıyorsak içimizin rahat olması gerekiyor. Keza bu kütüphaneyi kullanarak ortaya çıkarmak istediğimiz strateji de bu zaten, uygulamalarımızı olağan dışı hallerden korumak. Bu durumda sürekliliği garanti altına alan patternların değerlerini artırmak yerine gerekli konfigürasyonları sağlamak ve oluşan hatanın sebepleri incelenip hataya çözüm üretmek daha doğru bir yaklaşım olacaktır.
Peki optimum değerleri nasıl hesaplayabiliriz? Hystrix’in github sayfasında bununla ilgili bir formül ortaya konmuş.
Request per second at peak when healty** * **99th percentile latency in seconds** + **breathing room
Uygulamamıza ait metriklere sahipsek, gelen request sayıları ortalama olarak bellidir. Yoğun bir günde saniyedeki request sayısını, servisin responselarının %99 nu kapsayan süre(%99th percentile latency şeklinde geçer. Responseların %99’unun bu süreden az olması öngörülüyor.) ile çarparak nefes alacak kadar da bir ekleme sonucu ortaya bir değer çıkıyor. Bu değer optimal olmamakla birlikte başlangıç olarak bir fikir verebilir.
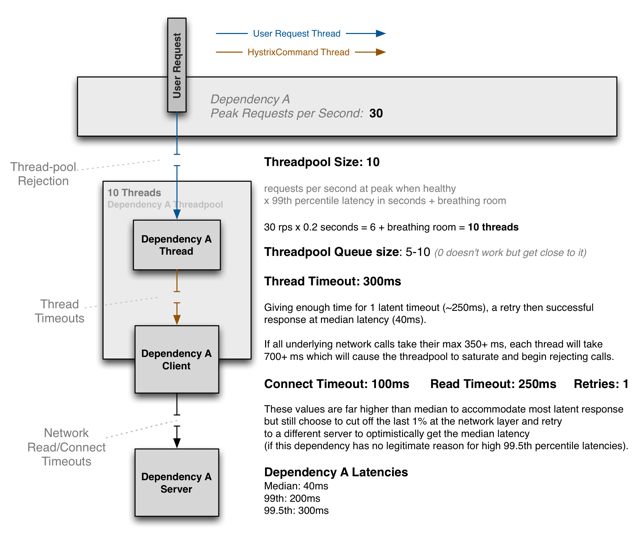
1.5 Tomcat ve Hystrix Thread Yönetimi
Tomcat ve Hystrix threadlerinin nasıl çalıştığını inceleyelim.
1.5.1 Tomcat configs
max-threads: Maksimum thread sayısı.
connection-timeout: Thread’in connection timeout süresi (ms).
min-spare-threads: Minimum hazırda bekleyen thread sayısı.
max-connections: Servera yapılabilecek maksimum bağlantı sayısı.
accept-count: Kuyrukta bekletilen bağlantı sayısı.
1.5.2 Threadler
Bir Hystrix command çalıştırıldığında Hystrix-commandname… şeklinde bir thread açılır. Buna paralel olarak HystrixTimer-… adında başka bir thread daha açılır. Timer threadi sizin komutunuz çalıştırıldığında timeout alıp almadığını kontrol eden threaddir.
Hystrix, her komut geldiğinde coreSize değerine kadar thread açar ve bu threadler de müsait olan Tomcat threadlerini kullanırlar. Hystrix coreSize değerine kadar her komutta diğer Hystrix threadleri müsait olsa dahi farklı bir Hystrix threadi açar.
Eşzamanlı olarak komut gönderildiğinde eğer Tomcat sunucusunda hazırda yeterli thread yok ise yeni Tomcat threadleri açılmaya başlanır. CoreSize değeri minimum Tomcat spare değerinden büyük olduğunda Hystrix threadleri halen Tomcat threadlerini tutmaya devam ettiği için var olan müsait Tomcat threadleri tekrardan minimum seviyesine inmez. Örneğin coreSize 20, Tomcat minimum spare thread değeri 15, maximum 25 olsun. Eşzamanlı gelinen 20 komuttan sonra bekleyen Hystrix threadi 20 olacaktır. Bu nedenle bekleyen Tomcat thread sayısı da 20 olacaktır.
CoreSize değeri aşıldığında maximumSize değerine kadar gelen istek adedince Hystrix yeni Hystrix threadleri oluşturur(Eğer allowMaximumSizeToDivergeFromCoreSize değeri true yapılmış ise). Bu sırada yeterli Tomcat threadi yok ise yeni Tomcat threadleri de açılır. Sonrasında keepAliveTimeMinutes değerine göre kullanılmayan Hystrix threadleri kendini terminate eder ve Tomcat threadleri de boşa çıkarılmış, kapatılmış olur.
Liveda tercih edilmeyecek bir yapılandırma olsa da eşzamanlı gelen isteklerin sayısı Tomcat maksimum thread sayısından fazla ama Hystrix threadpoolundaki maximumSize değerinden az ise, yapılan istekler reddedilmez ve çalışmakta olan threadlerin işini bitirmesi beklenir. Hystrix’teki timeoutInMilliseconds değişkeni bu konu ile bağlantılı değildir. Bu değişken komut başladığında bitmesine kadarki sürenin timeout değeridir. Burada Hystrix henüz kullanacak müsait bir thread bulamadığından dolayı beklemeye geçer. Boşta thread bulunduğu an komutu çalıştırır.
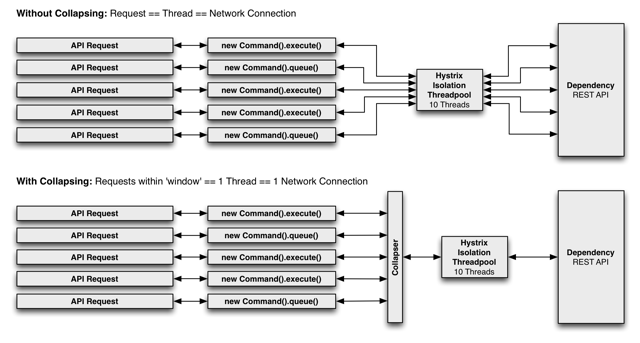
1.6 Request Collapsing
Hystrix’te çok kısa süren fakat yoğun istek alan servisler için Hystrix commandlerini toplayarak tek thread ve networkde kullanım mümkündür. Buna Request Collapsing denilmektedir ve Netflix’in ihtiyaçları neticesinde ortaya çıkmıştır. Normalde her Hystrix komutu bir thread açarak ilgili bağımlılığa gider ve istek gönderir. Çok kısa zamanlarda(histrix dökümantasyonunda 10ms ve daha az olarak belirtilmiş) birden fazla command geliyor ise bu requestleri toplayıp tek thread açarak ilgili bağımlılığa gitmek request collapsing ile mümkün olabilmektedir. Bu yöntemin kullanılmasının en önemli nedeni eş zamanlı çalıştırılan Hystrix commandleri için thread ve network connection kullanım sayılarını azalmaktır.
Netflix normalde tüm Tomcat threadlerinde bu yöntemi uygulamaktadır. Ayrıca tek bir user ve threadinde de bu yöntemin uygulanması mümkündür.
2.0 Use Case
Aşağıdaki gibi istekler gateway üzerinden X uygulamasına, oradan ise belirlenen uygulamalara rest istekler atarak istenen cevaplar dönülmektedir. Bu yapıda başlıca olabilecekleri sıralayalım.
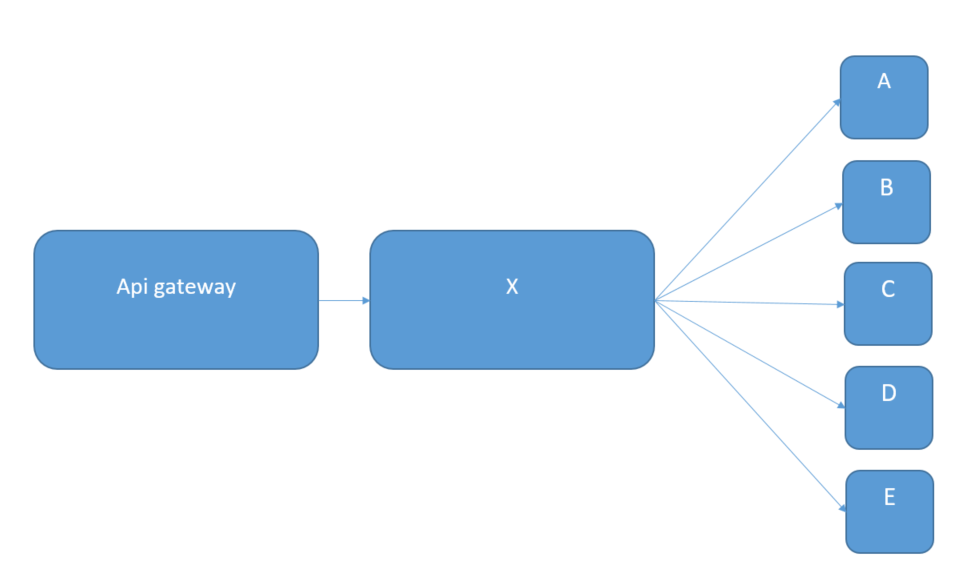
-
Her gelen istek X uygulamasından dağıtıldığı için herhangi bir bağımlılıkta beliren hata, geç cevap verme veya timeoutların uygulamadaki tüm threadleri kullanabilecek olması ve diğer uygulamalarda sorun olmamasına rağmen X uygulamasında kullanılacak thread kalmaması.
-
Bağımlılıklarda oluşan hatalarda veya timeoutlarda uygulamaları sürekli istekler ile boğma problemi. Ve akabinde ne yapılması gerektiği belirsizliği.
Ayrı ayrı uygulamalara circuit breaker patternini uygulayabileceğimiz gibi, X uygulamasına da hem circuit breaker hem bulkhead patterni uygulayabiliriz. Spring bize bazı anotasyonlar ile kolay bir şekilde Hystrix command oluşturarak yardımcı olmaktadır. Ancak anotasyonların kullanılamayacağı kadar dinamik bir servis çağırım tercihlerimiz mevcutsa nasıl circuit breaker uygulayabiliriz?
Örneğin senaryomuzda X uygulamasına gelen her isteğin uri bilgisinden hangi uygulamaya yönlendirilmesi gerektiğini ve bu işlemin hangi threadpoola gitmesi gerektiğini söylemek gerekiyor. Ana amaç tüketilen A,B,C,D ve E uygulamalarına giden isteklerin farklı threadpoollarda ele alınmasını sağlamak. Örneğin;
X uygulaması üzerinde A isimli bir threadpool oluşturarak değişkenleri tanımlıyoruz. Diğer uygulamalar içinde kullanması gereken threadpool özelliklerini belirliyoruz.
Bu değerlere göre gelen isteklerin farklı uygulamalara yönlendirilirken kaçar adet threadle bu işlemin gerçekleştirilebileceğini kontrol edebiliyoruz. Hysrix de A uygulamasına gelen çağrıların thread kullanımlarını sınırlayabilmemize olanak tanıyor. A uygulamasına gelen yoğun isteklerin ve akabinde timeout almaya başlamasıyla X deki tüm threadleri tüketmesini engelleyerek diğer isteklerin hala çalışabilmesini sağlıyoruz(bulkhead pattern).
Şimdi X uygulamasına gelen isteklerin nasıl dinamik olarak hystrix commandine çevrildiğini inceleyelim;
Bir factory classı yaratarak CircuitBreakerFactory extend edilmeli ve create metodu oluşturulmalıdır. Bunun yapılmasının sebebi her gelen istekte eğer konfigürasyonu yapılmamışsa ise yapılmasını sağlamak; eğer yapılmışsa da bu konfigürasyonla circuit breaker oluşturmaktır. Şimdi çağırdığımız yere bakalım;
“name” parametresi uygulama adıdır. A veya B gibi. A parametresini verdiğimizde factory yardımıyla bir komut oluşuyor ve A nın threadpoolunu kullanıyor.
Ayrıca bir fallback metodu tanımlanabilir. Circuit breaker açıldığında veya herhangi bir hatada istekler fallback metoduna düşer ve gerekli aksiyon alınmış olur.(Alert, log, default response gibi)
A için aşağıdaki değerleri baz alınırsa, son 20 istek değerlendirilecektir. 16 dan fazla istek hatalı ise circuit açılacak(tripped) ve diğer gelen istekler 2 sn boyunca reddedilecektir.
3.0 Sonuç
Bu yazımızda circuit breaker ve bulkhead patternlarını Hystrix bakış açısından inceleyip örnek konfigürasyonları ve dinamik kofigürasyon yönetimini inceledik.
Teşekkürler.